在 GitHub 全域数据下,如何进行项目活跃度分析排名是一件非常有意义的事情,不仅因为排名可以给人以更直观的感受,而且这种数字化的手段对项目进行定向优化有重要指导意义。本文则通过对 GitHub 全域数据进行建模,并利用之前的工作进行网络变换,之后通过加权 PageRank 算法计算了 GitHub 全域项目在 2019 年的活跃情况(为和 Octoverse 进行对比),并结合一些具体项目案例说明这个算法的有效性。
本文内容较长,对结果感兴趣的读者可以直接跳到「结果」部分查看一些最终的结论。
背景
我之前在 「Open Summit 2019 主题分享」和「GitHub 2019 数字年报项目」中都介绍了一种基于数值统计的全域活跃度计算方法。其基本思路为通过开发者行为数据的数量统计以及加权和的方式来直接计算项目的活跃度,这种方式目前也受到了大家的普遍认可。但其实这种方式明显的一个问题是,如果有人反复去刷一些行为事件,则可以人为的提升项目的活跃度,即项目活跃度的真实情况是难以评估的。
这开始这篇文章之前,先简单回顾一下之前的基于行为事件统计的计算思路和方法。在 GitHub 平台上,所有的行为都是公开透明可追溯的,所以我们可以通过统计分析开发者的行为数据来评估某开发者在某具体项目中的活跃情况。传统的仓库挖掘领域中,主要是以 Git 为主体展开的,所以主要指标是围绕 Commit 记录来看的,包括 Commit 数量、代码修改行数、文件修改数量等等。
然而 GitHub 等代码托管平台早已超出了代码托管的范畴,主要是以大规模协同开发与快速交付为核心的,所以我们就考虑以 GitHub 行为事件而非 Git 事件为主体来分析。而 GitHub 主要是以 Issue + PR 的方式进行沟通与协作的。故本人当时列出的五种主要事件为 Issue 评论、新建 Issue、新建 PR、PR Review 评论和 PR 合入,所以某开发者在某项目上一段具体时间内的活跃度计算方式为:$$A_d=\sum{w_i c_i}$$其中的 $A_d$ 为开发者活跃度,而 $c_i$ 为上述五种行为事件由该开发者触发的发生次数,$w_i$ 为该行为事件的加权比例,按照一个简单的价值评判,我们可以将这个值设置为 1 - 5,即 Issue 评论每个计 1 分,而 PR 合入一个计 5 分。在计算出每个开发者的活跃度后,可以通过一种加权和的方式来计算项目的活跃度,之前给出的方式是:$$A_r=\sum{\sqrt{A_d}}$$即项目的活跃度为所有开发者活跃度的开方和,这里开方是为了降低核心开发者过高的活跃度带来的影响。
在上述的计算方式中,无论是每种事件权重还是最终计算项目活跃度的开方运算,都是一种较为主观的计算方式。不仅权重可以根据社区自己的意愿来更换,而且加总时如果开方换成对数依然不会有太大影响,也是合理的。
然而众所周知 GitHub 其实是一个社交平台,其上的行为数据不仅仅可以用来进行一般的统计汇总,而且可以构成一个一般意义上的社交网络。那是否可以通过对这个网络进行进一步的分析,直接从开发者与项目的关系中分析出项目的活跃度呢?这就是本文想要进一步讨论的问题。
网络构建
想要从社交网络中计算全域项目活跃度,最基本的思路是先通过全域行为事件数据构造一个全域社交网络,然后通过一些经典的社交网络算法来进行分析。
二部图
构造网络的方式是多种多样的,最直接的方式是构建一个开发者和项目的二部图。即在一个异构图中,开发者和项目是两类节点,而所有的边都在这两类节点之间,即不会出现开发者之间的边或项目之间的边,这类图被称为二部图(Bipartite Graph),一个最简单的示例如下图所示:
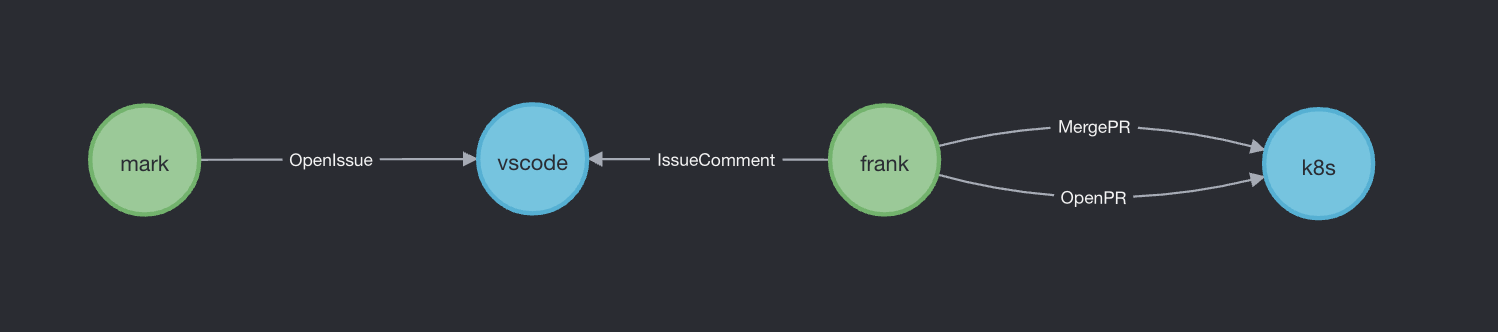
其中 vscode 和 k8s 是两个项目,而 Mark 和 Frank 是两个开发者,Mark 曾向 vscode 开过一个 Issue,而 Frank 既向 vscode 有过 Issue 评论,又向 k8s 有过 PR 的发起和合入。这就是一个最简单的二部图。而直接对于这种二部图进行分析是较为复杂的,传统的图算法大多是基于同质信息网络的,所以我们也可以对这个网络图进行降维,使其变为一个同质信息网络。
同质信息网络
同质信息网络的概念是相对于异质信息网络(Heterogeneous information network)而言的,而在异质信息网络的定义中,是对象类型种类大于 1 或者关系类型种类大于 1 均定义为异质信息网络。
而在我们上面构造的网络中,对象类型的种类(项目、开发者)和关系类型种类(Issue 活跃、PR 活跃)都是大于 1 的,所以需要在两个方面上都进行降维。
关系类型降维
依然假设我们只通过五种类型的行为事件数据构造了一个上述网络,则对于这个网络我们可以利用背景中的活跃度公式进行降维。对于开发者和项目之间的边,之前是包含各种不同的类型,例如 OpenIssue、IssueComment、OpenPR、MergePR 等,此时我们可以通过背景中的开发者加权活跃度计算公式,将所有的不同类型的边压缩成一中类型,即 Active,也就是活跃。而这条可以包含一个属性是该开发者在该项目上的活跃度。根据背景中的计算方式,可以算出 Mark 在 vscode 上的活跃度为 2,Frank 在 vscode 上的活跃度为 1、在 k8s 上的活跃度为 8,即变成了下图所示:
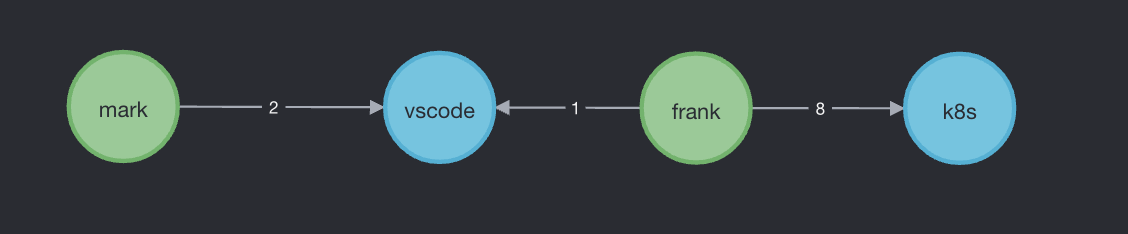
此时,虽然这个图依然是一个二部图,但其边类型已经被降成了一种类型,之后只要在进行一次节点降维,就可以将这个图转换为一个简单的同质信息网络了。
节点类型降维
接下来,我们继续进行节点降维。由于本文希望完成的是项目的活跃度计算,所以最终的图显然应该是以项目为节点的,故本次降维应该去除开发者节点。
我们可以从图中发现一种直观的计算项目关系的方式,即若两个项目上有相同的活跃开发者,则这个开发者在某种程度上就关联了这两个项目,关键问题是如何量化这种关联关系?我在「Open Summit 2019 主题分享」中曾经提到有过对全域项目进行基于模块度的聚类工作,事实上解决的同一个问题,即如何通过开发者在项目上的活跃情况来计算两个项目之间的关联度。这里依然采用之前的方式,即使用开发者在两个项目上的活跃度的调和平均作为该开发者对两个项目关联度的贡献,即:$$R_{ab}=\sum_{dev}{\frac{A_{da}A_{db}}{A_{da}+A_{db}}}$$也就是说,a、b 两个项目的关联度,为所有在两个项目上同时活跃过的开发者在两项目上的活跃度调和平均和。这里的 $A_{da}$ 其实是上述活跃度开方的结果,即同样使用了背景中介绍的方法来降低某些高活跃开发者对结果造成的影响。如下所示:
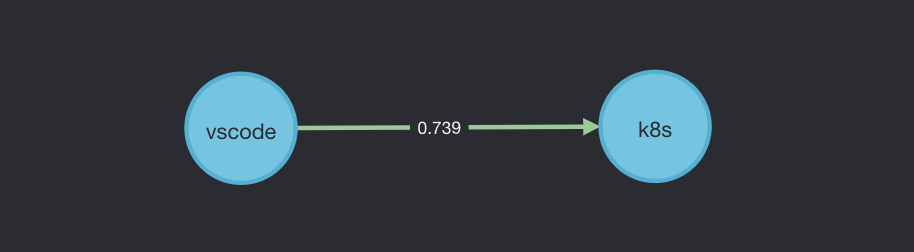
可以看到,在上述图例中,由于 Mark 只在 vscode 项目中活跃,所以不对两个项目的关联度有贡献,而 Frank 在两个项目中均有活跃,所以可以对两个项目关联度有贡献,且贡献值是 $\frac{\sqrt{8}}{1+\sqrt{8}}=0.739$。通过这种方式,则可以将开发者从图中移除,而构成一个仅包含项目和它们之间关联度的同质信息网络图。
活跃度计算
在通过上述方法构建了 GitHub 的巨大全域同质网络图之后,接下来就是如何分析这个巨大的图。本文采用了加权 PageRank 算法(Weighted PageRank,后称 WPR)进行计算。
PageRank 算法是以 Larry Page 命名的,是 Google 最著名的网页排序算法。网络上有大量的 PageRank 的算法介绍,本文不再赘述。经典的 PageRank 算法是进行有向无权图计算的一种算法,边是网页之间的链入关系。
而在本文中,首先各节点之间其实是无向的,即项目之间的关联关系是相互的,也就是 $R_{ab}=R_{ba}$。其次是带权图,即每两个项目之间的关联度都是有一个量化指标的,这个指标确定了两个项目之间的关联紧密程度,故经典 PageRank 算法并不能直接适用。于是引入了 WPR 算法,WPR 算法在经典的 PageRank 算法中引入边权,即迭代计算时,节点中心度的值不再平均分配到相邻节点,而是通过边权来确定分配比例。
另外,由于 WPR 也是计算有向图中心度的,所以我们在建立边时,将同时建立两个项目指向彼此一条有向边,而且边权是相等的,均为上述计算出的两个项目的关联度。
本文没有对 WRP 算法做修改,直接对构建出的网络进行了全域计算。但由于 GitHub 上存在大量的自动化机器人账号,可能对项目关联度造成影响,故在建图后过滤了当年活跃数量大于 200 个项目的开发者账号的数据。
结果
总体数据
本文对 GitHub 全域共计 6 亿条行为日志数据进行了分析。
2019 年 GitHub 活跃仓库数共计 3972.3W 个,活跃开发者账号共计 1193.3W 个。在根据上述活跃度计算公式过滤五种行为事件后,活跃仓库数共计 138.6W 个,活跃开发者账号共计 212.1W 个。根据开发者活跃项目数量,剔除当年活跃数量大于 200 个的开发者账号共计 173 个,则剩余活跃仓库数量共计 870249 个。
最终构成的项目关联度网络中节点数量为 870249 个,边数量为 4320.3W 条。
连通性
对于上述构造的图,首先进行了连通性分析。总共包含 30870 个强连通分量,其中最大的连通分量包含 786659 个项目,即 GitHub 中 90.4% 的项目在上述关联度定义下是连通的,剩余 83590 个项目分成了 30869 个独立的分图,其中最大的连通分量包含 156 个项目,其他大部分项目为单项目节点,即与其他任何项目都没有产生关联。
对其中项目数大于 50 的连通分量进行进一步观察,发现大部分项目为测试项目,可能由一个账号批量创建的。而另外的群落则表现出明显的地理隔离,其中较大的一些隔离群落分别来自日本、俄罗斯、法国、乌克兰、白俄罗斯,未发现有中国开发者群聚而出现地理隔离的情况。说明语言障碍很可能是导致发生开源社区隔离的一种重要原因。
有意思是其中有一个连通分量是一家公司,即这个公司的所有开发者在 2019 年中未在其他 GitHub 项目上活跃过,而其他开发者也未在这个公司的项目中有过活跃。
中心度
本处暂不区分中心度与活跃度的概念。使用 WPR 算法进行中心度计算,获得 2019 年活跃度最高的 20 个项目如下所示:
| # | Repo | PageRank |
|---|---|---|
| 1 | microsoft/vscode | 1135 |
| 2 | flutter/flutter | 645 |
| 3 | kubernetes/kubernetes | 624 |
| 4 | DefinitelyTyped/DefinitelyTyped | 564 |
| 5 | microsoft/TypeScript | 544 |
| 6 | tensorflow/tensorflow | 535 |
| 7 | gatsbyjs/gatsby | 504 |
| 8 | golang/go | 448 |
| 9 | rust-lang/rust | 448 |
| 10 | facebook/react-native | 426 |
| 11 | helm/charts | 415 |
| 12 | MicrosoftDocs/azure-docs | 390 |
| 13 | ansible/ansible | 386 |
| 14 | NixOS/nixpkgs | 378 |
| 15 | pytorch/pytorch | 362 |
| 16 | home-assistant/home-assistant | 358 |
| 17 | Homebrew/homebrew-core | 357 |
| 18 | aspnet/AspNetCore | 352 |
| 19 | nodejs/node | 347 |
| 20 | dotnet/corefx | 333 |
而 GitHub Octoverse 发布的 2019 年全球 Top 10 活跃项目的排名如下:
| # | Repo |
|---|---|
| 1 | microsoft/vscode |
| 2 | MicrosoftDocs/azure-docs |
| 3 | flutter/flutter |
| 4 | firstcontributions/first-contributions |
| 5 | tensorflow/tensorflow |
| 6 | facebook/react-native |
| 7 | kubernetes/kubernetes |
| 8 | DefinitelyTyped/DefinitelyTyped |
| 9 | ansible/ansible |
| 10 | home-assistant/home-assistant |
可以看到,虽然排名略有差异,但 GitHub 发布的 Top 10 项目中除 firstcontributions/first-contributions 项目外,另外 9 个项目均在 WPR 算法计算的 Top 20 之列。下面,我将以该项目为例,说明一下为什么这个项目是一个例外,它与其他 9 个上榜项目之间有什么差别。
案例分析
microsoft/vscode
在进入对 firstcontributions/first-contributions 的分析之前,我们先看一下世界第一项目 microsoft/vscode。该项目的 PageRank 值一骑绝尘,是第二名 flutter/flutter 的将近两倍,我们看一下与其关联度最高的 10 个项目的情况。
| # | Repo | Relation | PageRank |
|---|---|---|---|
| 1 | microsoft/TypeScript | 799 | 544 |
| 2 | microsoft/vscode-remote-release | 594 | 162 |
| 3 | microsoft/vscode-python | 458 | 157 |
| 4 | DefinitelyTyped/DefinitelyTyped | 410 | 564 |
| 5 | Microsoft/vscode-cpptools | 360 | 102 |
| 6 | microsoft/terminal | 323 | 243 |
| 7 | electron/electron | 255 | 256 |
| 8 | flutter/flutter | 236 | 645 |
| 9 | microsoft/vscode-docs | 227 | 40 |
| 10 | gatsbyjs/gatsby | 220 | 504 |
可以看到,这里已经体现出了一个惊人的网络关系,在该项目关联度最高的 10 个项目中,有多达 4 个项目是与其一同处在全球 Top 10 中的项目,包含了编写 vscode 的语言项目 TypeScript、与 TypeScript 高度相关,给 Node.js 类库添加类型说明的 DefinitelyTyped、Google 开源的跨平台应用开发框架 flutter、基于 React 的快速开发框架 gatsby,而该项目与自己的开发语言之间的关联度高达近 800。可以看到 vscode 与一众顶级项目一起,构成了一个非常庞大的开源社群,他们之间关系密切而又相互促进,吸引着世界上最优秀的开发者共同参与其中。
firstcontributions/first-contributions
从上面的结果中可以看到,该项目因贡献者众多而出现在了 GitHub Octoverse 2019 的报告中,排名全球第四,然而在 WPR 算法下,该项目甚至未能排入 Top 20,那么我们先看一下该项目在 WPR 算法的排名情况:
| # | Repo | PageRank |
|---|---|---|
| 532 | firstcontributions/first-contributions | 49 |
我们可以看到,这个项目在本算法下的全球排名是 532 位,PageRank 值仅有 49。那么到底是什么原因导致了这个项目的排名在不同的算法下差距会如此之大呢?这与这个项目本身的特性有很大关系。
该项目为一个 GitHub 学习型项目,里面包含了数十种语言的如何提交 GitHub 第一个 PR 的教程,由于该项目异常火热,故大量初学者会选择用该项目来学习提交 PR,故在项目上产生了大量的贡献者。所以当 GitHub 以活跃贡献者数量排名时,该项目排行全球第四,但当使用 WPR 进行中心度计算时,该项目的排名则大幅降低,我们可以看一下其中的原因。
我们查看一下与该项目关联度最高的 10 个项目,以及他们的关联度和这些项目的 PageRank 值,如下表所示:
| # | Repo | Relation | PageRank |
|---|---|---|---|
| 1 | freeCodeCamp/freeCodeCamp | 28 | 77 |
| 2 | pandas-dev/pandas | 15 | 195 |
| 3 | firstcontributions/firstcontributions.github.io | 15 | 4 |
| 4 | gatsbyjs/gatsby | 11 | 504 |
| 5 | publiclab/plots2 | 10 | 52 |
| 6 | scikit-learn/scikit-learn | 9 | 138 |
| 7 | ows-ali/Hacktoberfest | 9 | 3 |
| 8 | systers/mentorship-backend | 9 | 5 |
| 9 | Ishaan28malik/Hacktoberfest2019 | 8 | 5 |
| 10 | danthareja/contribute-to-open-source | 8 | 4 |
我们可以看到,其中仅有 5 个项目的 PageRank 值高于该项目,而且除 gatsbyjs/gatsby 较高进入全球 Top 20 外,其他项目的值均不高,更关键的是该项目与这些项目之间的关联度都很低,即便是关联度最高的 freeCodeCamp/freeCodeCamp 也只有 28。而一般强关联项目的关联度均可到达到数百甚至上千,例如关联度最高的 kubernetes/kubernetes 与 kubernetes/enchancements 两个项目的关联度高达 1815。
这其中的原因可能包含两个:
- 由于这是一个学习型项目,所以活跃在项目上的开发者均为 GitHub 的初学者,他们并不会在短时间内成为其他顶级项目的核心开发者,所以该项目很难与各种顶级项目之间产生关联。
- 同样由于这是一个学习型项目,所以大部分开发者与该项目的关联都是一次性的,所以即使少量的初学者后来成为了顶级项目的开发者,由于与该项目的关联较弱,所以不会导致该项目与顶级项目之间产生强关联,例如
gatsbyjs/gatsby虽然自己的排名很高,但与该项目的关联度只有 11,所以很难对该项目的排名产生质的影响。
这个项目在 Octoverse 与本文算法下的排名对比很好的诠释了本文算法的优势,即开发者与项目、以及项目之间的通过开发者的行为关联了起来,而利用之前的一些工作,这些关联被很好的量化,最终产生了一个价值网络。在这个价值网络中,有价值的项目和开发者被关联在一起,并可以直接通过算法进行计算和排名,对未来的各种工作打下了良好的基础。
Wuhan2020
虽然为了和 Octoverse 2019 对比文本主要做的 2019 年全年数据,但同时也对 2020 年数据进行了分析统计,并对由 X-lab 实验室发起的 Wuhan2020 项目做了一些分析。
虽然仅活跃了一到两个月,但该项目在 2020 全年排名全球截止到 10 月初为全球 1334 名,优于目前大部分国内项目,可视化了一下与该项目相关的一些项目,可视化后可以根据项目之间的关联直接肉眼分辨出不同的开源社群,如下图所示:
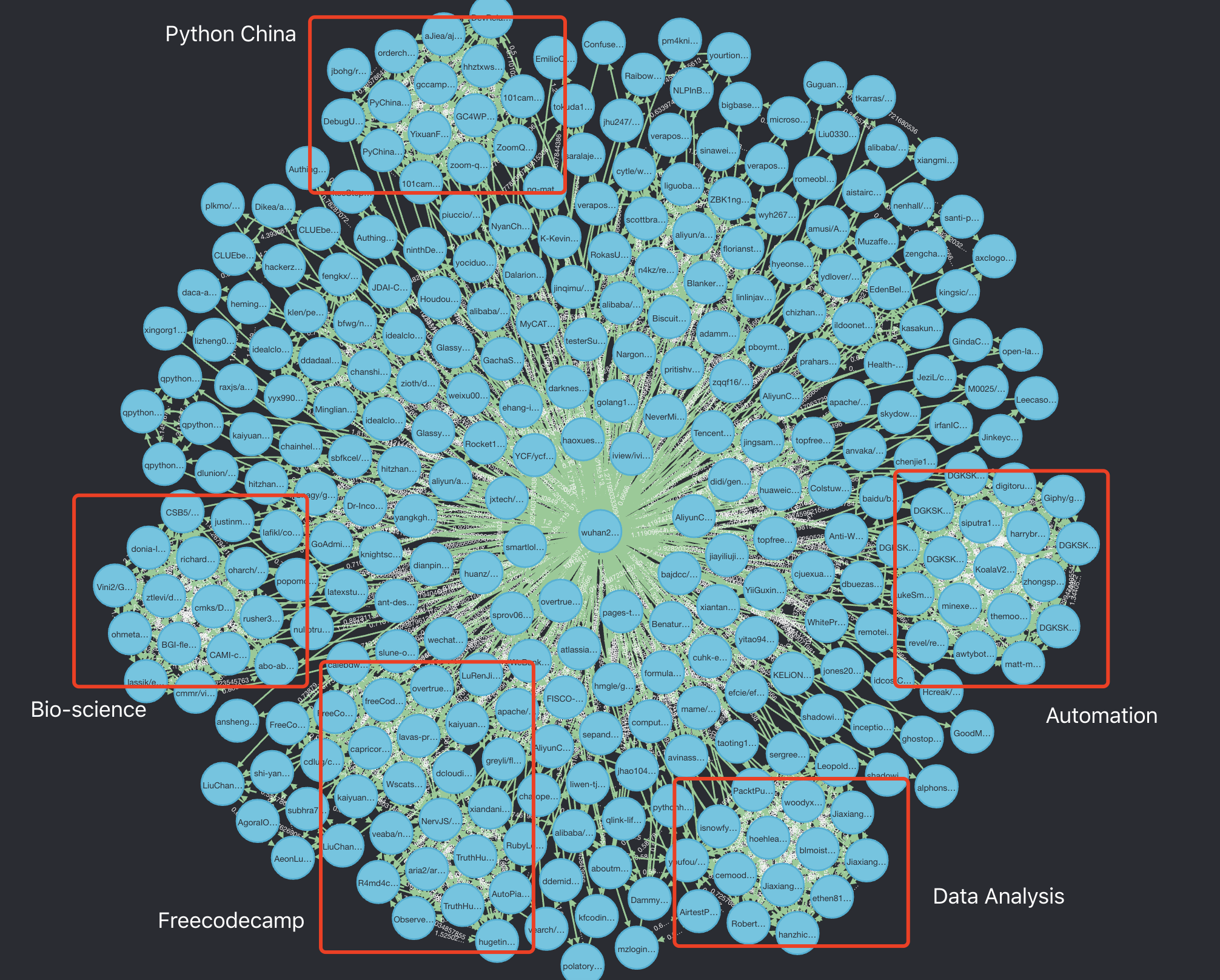
可以看到关联较多的项目会自动聚成群落,左上角是以 PyChina、101camp(蟒营),即 Python 中国社区;左侧的多个项目,点开后均为生物技术相关,例如 DNA 测序、碱基匹配等;左下角则为 Freecodecamp 社区和前端项目阵营;右下角为数据分析社群,有数个经常参加数据分析比赛的账号关联在一起;右侧为一个自动化群落,里面的大部分项目都与流程自动化有关。而无疑这些项目的开发者都是在 Wuhan2020 期间对项目有过巨大帮助的社群,这里要再次感谢。
而如果我们直接去获取与其关联度最高的项目,我们会看到除了 wuhan2020 组织下多个项目之间高度关联外,还与 Homebrew 的多个项目、Kubernetes 的多个项目以及阿里的 docsite 项目、Hypertrons 项目等有关联。其中 Homebrew 的关联主要来自于社区中陈睿的活跃,他是来自 Homebrew 的 GitHub Pro,以非常低调的姿态帮助社区构建了社区的 GitHub 规范、action 流程自动化等。而 Kubernetes 和 docsite 则要感谢阿里巴巴各位同学的关注与帮助,社区官网便是 docsite 负责人亲手搭建的。Hypertrons 项目也为本人发起的一个开源流程自动化机器人项目,在 wuhan2020 中也发挥了一定的自动化功能。
回顾年初的经历,一切都还历历在目,再次感谢大家在 wuhan2020 项目中的付出。
其他说明
为何没有直接对异质网络进行分析?
通过开发者对项目的行为事件构建的完整二部图的分析,可能可以挖掘出一些较为隐秘的信息。对于异质信息网络的分析,尤其是基于网络嵌入(Network Embedding)模型的分析是当下非常热门的。但对于这类领域知识较为完备,可以通过专家经验建模的领域,个人还是比较看好直接进行建模并通过传统算法来分析的方式,但并不排除之后使用较新的 HIN 相关算法进行创新尝试。
为何没有对项目节点进行活跃度计算?而是绕了一圈先通过活跃度计算了项目关联性?
最初考虑过直接对项目节点活跃度赋值,然后根据网络关联进行活跃度再分配。但在传统的中心度计算中,PageRank 作为一种非常有效的算法,其最大的特点就是初值无关性。即即使对项目节点进行了活跃度的初值赋值,最终的结果依然只取决于网络关系。故将重心转移到计算项目关联度上,而关联度的计算则也使用了统计活跃度公式,所以虽然是曲线救国,但是较为合理的结合了之前的工作和 WPR 算法。
之前提到机器人账号过滤,为什么需要过滤?不精准的过滤会对结果有什么影响?
协作机器人已经是顶级开源项目中的标配,可以用来帮助做项目的标准化协作管理与流程自动化。一些优秀的通用机器人可能服务的仓库数量巨大,例如做自动依赖更新的 dependabot 服务数据仓库数量高达 148W 个,这会导致在大量的项目之间建立起关联。而更糟糕的是对于世界顶级项目,一旦它们使用了相同的机器人,由于这些项目活跃度很高,机器人的活跃也会较高,就会导致顶级项目之间产生高度关联,这会对最终的结果产生质的影响(例如 vscode 与 flutter 的关系密切,可能与这个有关)。
所以如果之后我们可以对机器人账号有更加精准的判断和剔除方法,则可以帮助我们进一步提升结果的准确度,尤其是在未来对相似性或聚类分析有巨大帮助。而本文采用粗滤一是因为没有更好的手段进行过滤,二是因为这种关联度的误差虽然对相似性分析有巨大影响,但个人感觉对中心度分析的影响相对较小。
未来展望
本次实验是基于统计数据进行进一步网络分析的第一次探索,还可能包含大量的其他工作,目前可以预见的工作包含:
- 是否可以直接使用 Network Embedding 等对异质信息网络进行分析而不需要进行降维转换?
- 是否可以给出异质网络下的 PageRank,使价值网络直接在开发者与项目之间流转,而无需进行降维转换?
- 是否可以更加精准的判断机器人账号,从而消减由于机器人活跃带来的关联度影响?