由于一直在使用 Neo4j 的社区版进行 GitHub 行为日志图数据的相关开发工作,中间还是踩了不少坑,即便有些是数据库使用中常见的坑,但总还是会不经意踩到,所以记录一下。
背景
这里记录的是在 Neo4j 社区版上进行 GitHub 全域数据图分析的一些问题。主要的步骤包含:
- 从 Clickhouse 数据库进行数据预处理和读取,并导入到 Neo4j 图数据库中。
- 对于导入的数据进行 OpenRank 的计算,包含建图和计算两个步骤。
总体数据量为:2015.1 - 2022.2 全域所有数据,节点为有过活跃度中定义行为的开发者和仓库,边为开发者和仓库之间的活跃信息。总量为 39,970,303 个节点,72,354,900 条边。
数据导入
GitHub 的活跃度数据是以月为维度进行统计并导入图数据库的,数据导入部分的包含了如下几个步骤:
- 以月为维度统计所有开发者在所有仓库上的活跃度数据,同时获取最新的仓库名、组织名、开发者账号、仓库语言、许可证、描述信息、star、fork 数据。
- 将上述的节点信息,包含仓库的名称、组织名、语言、许可证、描述信息、star、fork 以及开发者的账号信息更新或插入到仓库中。
- 根据活跃度数据在节点之间建立相应的边,并设置活跃度属性。
- 对仓库、开发者、活跃关系上的活跃度建立索引,以方便后续使用。
在数据导入部分,总体而言较为顺畅,目前 7 年的所有历史数据导入仅需 4 小时左右,网络情况较好时则更快,但需要注意以下几点:
- 数据读取时尽量在 Clickhouse 的返回信息中筛选掉不需要的数据,由于数据量较大,每月的活跃度数据条目在 2015 年大约在 50W 条,到 2022 年初已经到 300-400W 条每月,所以任何一个冗余的字段都会消耗大量的网络流量。
- 数据的读取和导入可以并行进行,在导入当月数据时就可以开始加载下月的数据,则在网络情况较好时,可以连续导入而无需等待数据。
- 由于一个开发者可能在多个仓库中活跃,而一个仓库也可能有多个开发者活跃,所以更新数据时,不要直接按每行去更新,而可以先更新仓库和开发者的基本数据,之后更新边,可以减少仓库和开发者的属性更新次数。
- 虽然之后需要通过仓库名、开发者账号、组织名、语言等进行查询,也不要在导入前预先在这些需要频繁更新的字段上建立索引,因为属性更新会导致索引重算。因此如果预先建立索引,则大规模的频繁更新一定会导致导入速度变慢。
- 对于数百万节点和边的属性更新,不要反复发起请求,而应该在一个请求中完成,可以直接使用
UNWIND进行更新。
数据导入部分的在每个月的时间消耗如下图:
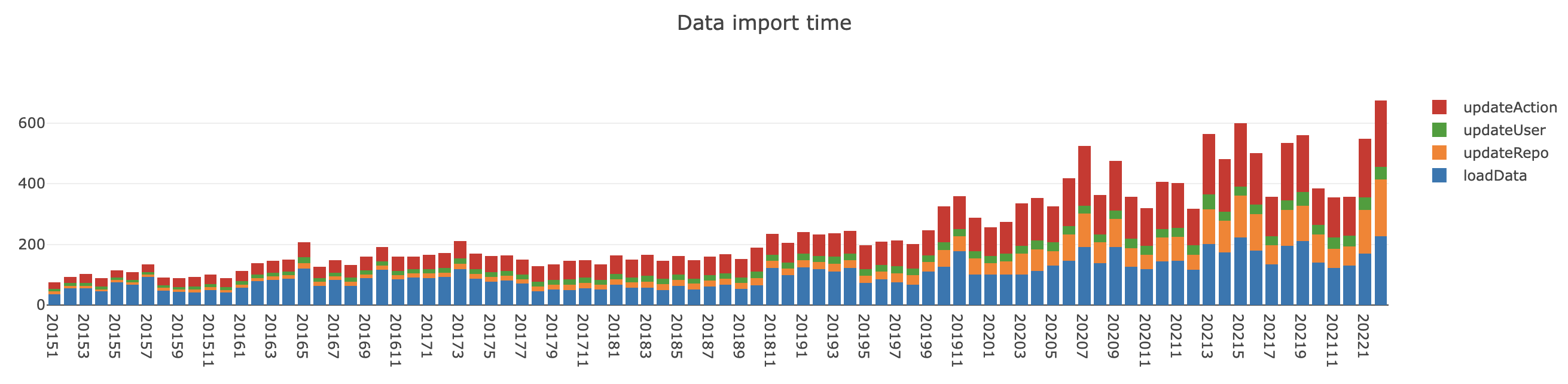
总体而言,导入速度是可以接受的,即使最后一个月的导入时间也在 10 分钟左右,且由于并行进行数据读取和导入,事实上数据读取(laodData)的时间是可以忽略的,而总导入时间大约为 4 小时。
OpenRank
OpenRank 是一种类似于 PageRank 的排序算法,目前的实现是基于 Neo4j 的 GDS Pregel 框架开发的,基本流程是:
- 由于 Pregel 是一个 Node-centric 的计算框架,所以第一步是要对于每个月的协作网络进行内存建图。建图时需要处理异质边,进行边权的归一化与同质化。
- 利用 OpenRank 对当月全域节点进行价值计算,并将结果写回。
- 对当月没有活跃的仓库和开发者,如果上个月存在 OpenRank 值,则按一定比例继承到当月。
- 对当月仓库、开发者 OpenRank 属性建立索引,以方便后续使用。
OpenRank 的计算,前半段的速度甚至要快于数据导入,但到后半段速度骤然减慢,之后会详细分析一下原因。这中间需要注意的点有:
- 对于某些可能存在也可能不存在的数值类属性,建立索引后方便快速查询,例如建图时要快速过滤出在当月有过活跃的仓库和开发者,此时如果使用
r.activity IS NOT NULL事实上不会利用到数值索引,需要使用r.activity > 0才会使索引生效。可以使用EXPLAIN去观察二者的不同,在 db hits 的数量上差距也较大。前者的使用的是NodeIndexScan,即对当前索引的完全扫描,而后者是NodeIndexSeekByRange,即按范围查询,速度更快。 - 对于当月不活跃的开发者和仓库,需要按照上月的 OpenRank 值按比例继承,此时可以使用
apoc.periodic.iterate方法,可以分批次进行更新,以避免在一个事务中提交过多更新而速度变慢。同时这个方法要注意在使用时是否打开并行,社区版最多可以支持 4 核并行,但如果不同的更新语句可能会影响到同一个节点,则打开并行可能导致死锁,因为 Neo4j 在更新时会加行锁,但由于此处对节点的更新是完全独立的,因此可以开启并行更新以加快速度。
关于性能骤降问题
在计算 OpenRank 时,计算到后期会出现性能骤降的问题,我对运行日志进行了分析,得到运行时间的变化图如下:
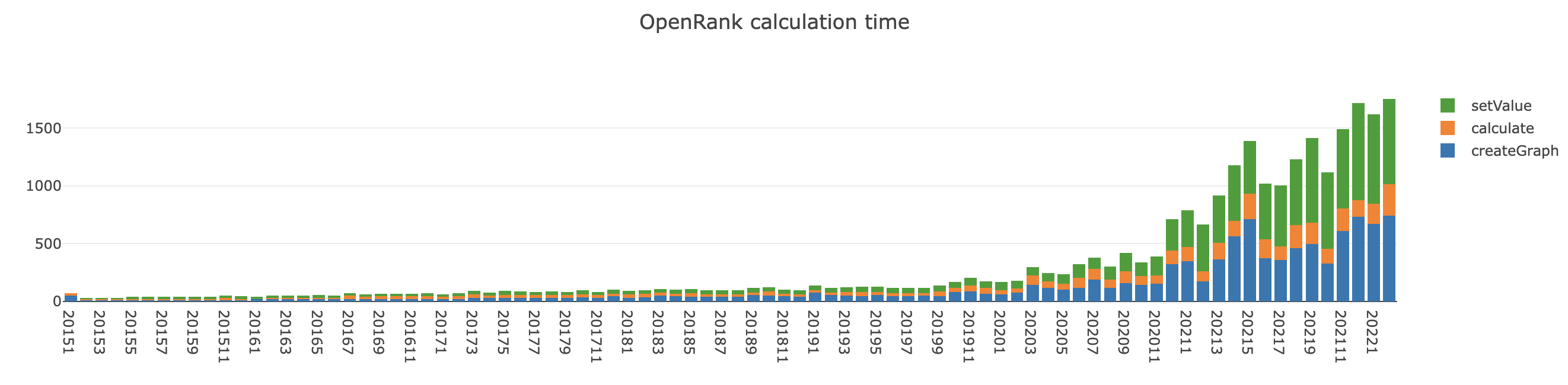
可以看到,大约从 2020.3 开始,计算每月 OpenRank 所使用的时间突然大幅增加,从每月平均 2min 左右降到 2022.2 的大约 30min。
其中 createGraph 为内存建图时间,calculate 为计算/写回时间,setValue 为更新不活跃节点的 OpenRank 值所使用的时间。
其中 OpenRank 本身的纯计算时间是极短的,虽然设置为最大迭代 40 次,但基本都在 13 次迭代左右时收敛,从 2015.1 的 2s 左右到 2022.2 的 4s 左右,OpenRank 的计算时间是可以忽略不计的。
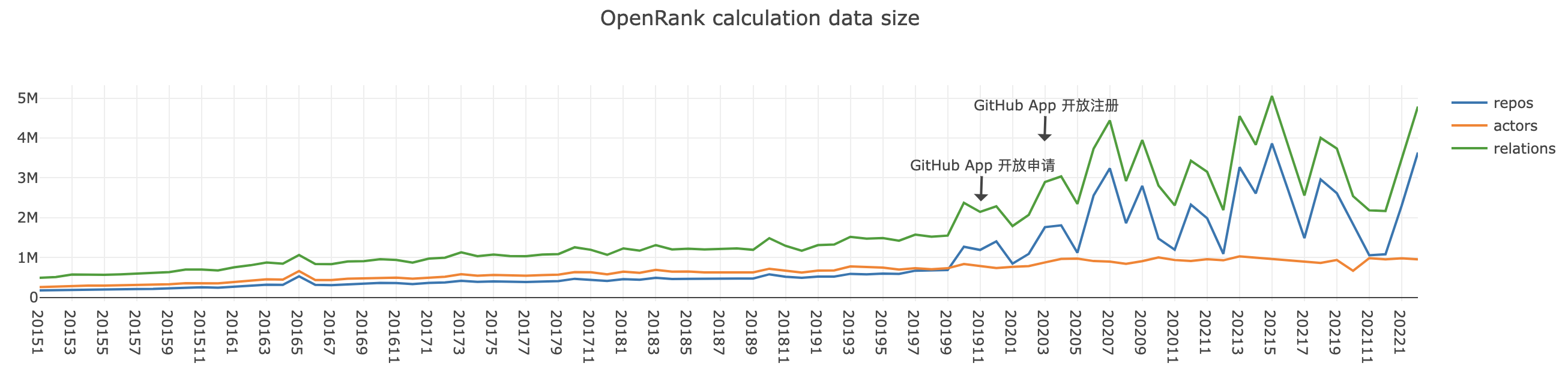
虽然随着时间的推移,每个月计算的数据量是不断增加的,可以看到下图是每个月参与计算的节点数量和边数量的变化情况,但应该不是导致如此急剧的性能下降的唯一因素。
2022.3.22 UPDATE:从数据上可以看出,GitHub APP 上线导致协作网络图规模大幅增加,如 dependabot 在 2020.3 开始每月会在超过 100W 的仓库上提交 PR。
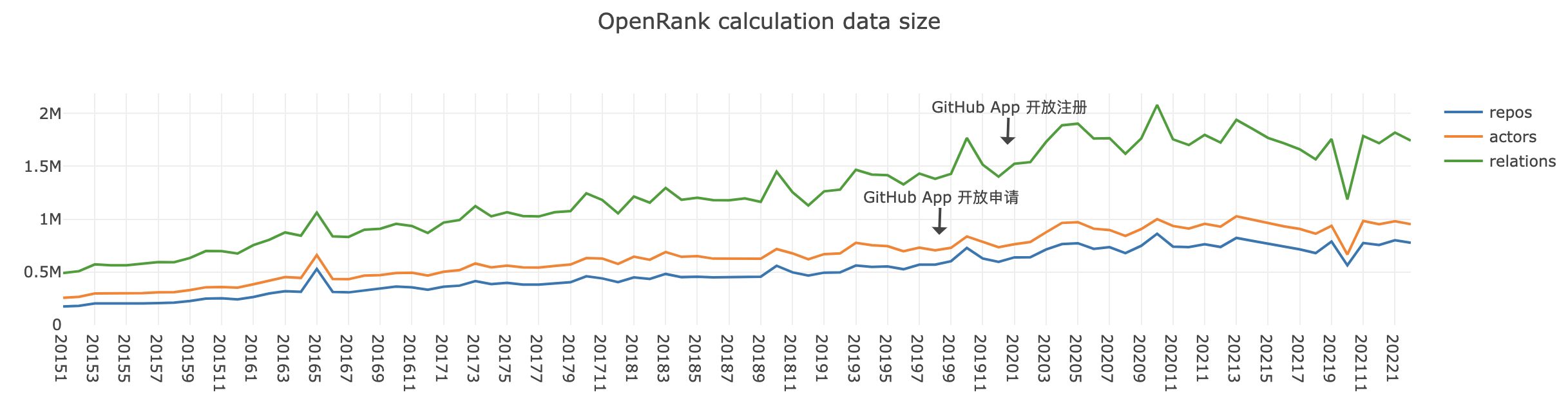
2022.3.23 UPDATE:观察到 GitHub APP 导致的数据问题后,重新进行一次数据导入与计算,去除所有 GitHub APP 的相关日志,可以看到数据量的增长较为平缓。而数据量减少会导致所有相关时间的减少,在去除机器人数据后,数据导入可在 2.5 小时左右完成,而导入加计算则可以在 6 小时内完成,2022.2 的总体计算时间大约在 10 分钟。
通过观察发现,可能是由于数据库的数据量增大,使得整张图无法被全部加载到内存,而 OpenRank 算法是对全域节点进行计算的,因此可能在读写节点和边的信息时出现了缓存不命中的情况,从而频繁换页导致磁盘 I/O 引起了性能问题。
因此我对后期正在进行的运算过程进行了一些采样,通过当前正在进行的 Query 的信息,可以看到发现一些问题:


以内存建图时节点读取为例,在性能开始变慢时,进行了一次采样,发现 pageFaults 开始变大,此时 pageFaults/pageHits 大约为 1.7% 的不命中率,而到 2022.2 时,该比例已经到达了 13.2% 。
另外,从更细粒度的时间统计上来看,在 2022.1 时,仅建图读取节点信息而言,前 77% 的节点加载仅用时 9s,之后速度明显变慢,后 23% 的节点加载用时 44s,而且不确定是否是 Neo4j 的读取策略问题,在出现缓存不命中后,边的读取速度会大幅度下降,比起节点要慢得多。
因此基本肯定是由于全体数据量已经大于内存限制,因此导致换页而发生了性能骤降,目前除提升内存上限外尚没有更好的方法。
但由于缓存机制,一些具有局部性的查询依然是可以通过缓存加速的,只是由于 OpenRank 算法的特殊性,需要全域节点参与计算才会导致该问题。
结论
在较大数据规模的数据集上做相关开发时,很多微小的工程疏漏都会被放大,从而导致系统的整体性能严重下降,因此需要在每一步设计时做到足够细致,才能做到快速迭代。
另外由于考虑到分布式可能带来额外的工程开发量和一定的 overhead,所以当时选择了 GDS 开发,但受到单机硬件规模的限制,可能未来还是会切到图数据库存储 + 分布式 Spark 图计算引擎的方式,好在 Pregel 框架提供了很好的实现范式,可以很方便的在 Spark 中重新实现 OpenRank。