UPDATE 2023-03-16 我也已经将 DocsGPT 的能力集成到了我们实验室的浏览器插件项目中,大家可以在浏览器中访问 GitHub 仓库页面时直接看到对应的聊天窗口,并使用当前的项目文档进行问答。插件项目地址在这里,Chrome 插件安装地址在这里,Edge 插件安装地址在这里。支持的项目列表和效果预览可以看这篇博客。
缘起
从去年底开始 ChatGPT 火爆出圈,大家都在思考如何利用 ChatGPT 的能力来构建自己的应用,我也在想,如果有一个机器人可以学习一下开源项目文档中的信息,那是否就可以作为一个开源项目的问答机器人了呢?
这个想法一直在我脑海里,直到看到了有人已经进行了实现,也就是 DocsGPT,这个项目开源一个月已经收获了 3000+ star。
我自己也想试一下,于是按照文档也部署了自己的一个实例,并且添加了一部分项目的文档进去。大家有兴趣的可以访问OSS-GPT 进行尝试,看看效果如何。
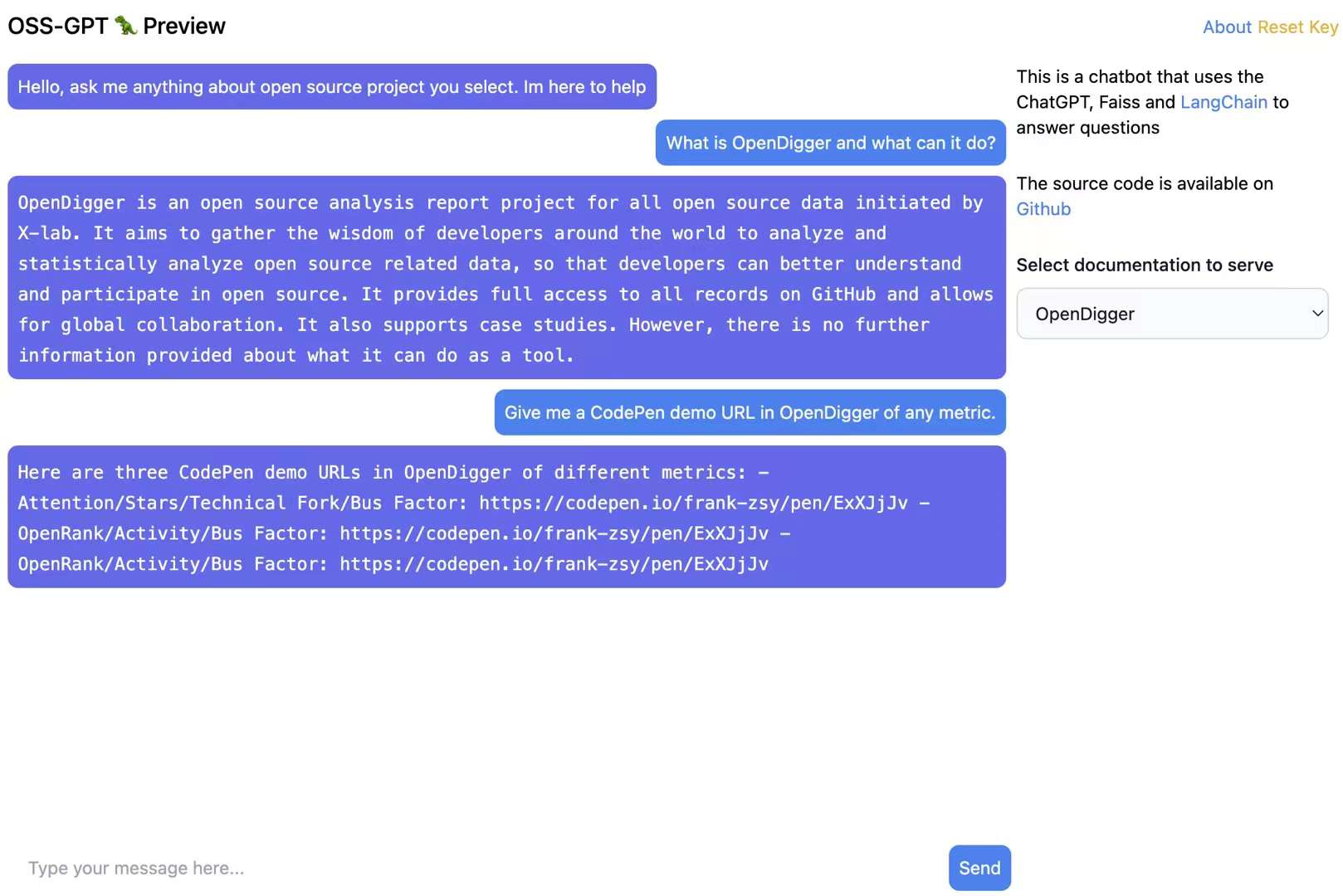
DocsGPT 中 OpenDigger 文档的问答效果。目前支持的项目包括:OpenDigger,OpenYurt,Egg.js,Midway.js,NebulaGraph,OceanBase,OpenSumi 等。
深究
按照 DocsGPT 的 Wiki 训练了几个自己熟悉的项目文档后也发给相应社区的负责人试用了一下,发现效果差强人意,有时候还是比较智障的,于是想深入探索一下背后具体是什么原理。
ChatGPT 的使用方法
说到具体的实现方法,首先要提到 ChatGPT 是如何使用以及有哪些限制的。
ChatGPT 提供了非常简单的 API 接口可以用来做聊天任务,底层使用的是 gpt-3.5-turbo 大模型,这个模型使用的训练数据本身是较老旧的互联网信息(截止到 2021.9),所以它并不具有一些较新的信息,更不要提非公开的信息了。
因此 ChatGPT 提供了通过 prompts 来进行提示的方法,也就是在发起请求时,可以带上一段信息。由于是一个聊天接口,因此可以包含多个聊天的内容。其中包括来自系统的提示:例如用来描述一下 ChatGPT 现在是什么角色,应该具有什么样的语言风格等。另外还可以包含一些用户的历史聊天记录,就像背景知识一类的,都可以作为用户的输入带进去,这样可以使得 ChatGPT 在本次聊天中具有了领域知识与上下文信息。通过这种 prompts 的方式,可以对 ChatGPT 有一定的定制能力,并使用其大模型的自然语言能力来组织回答信息。
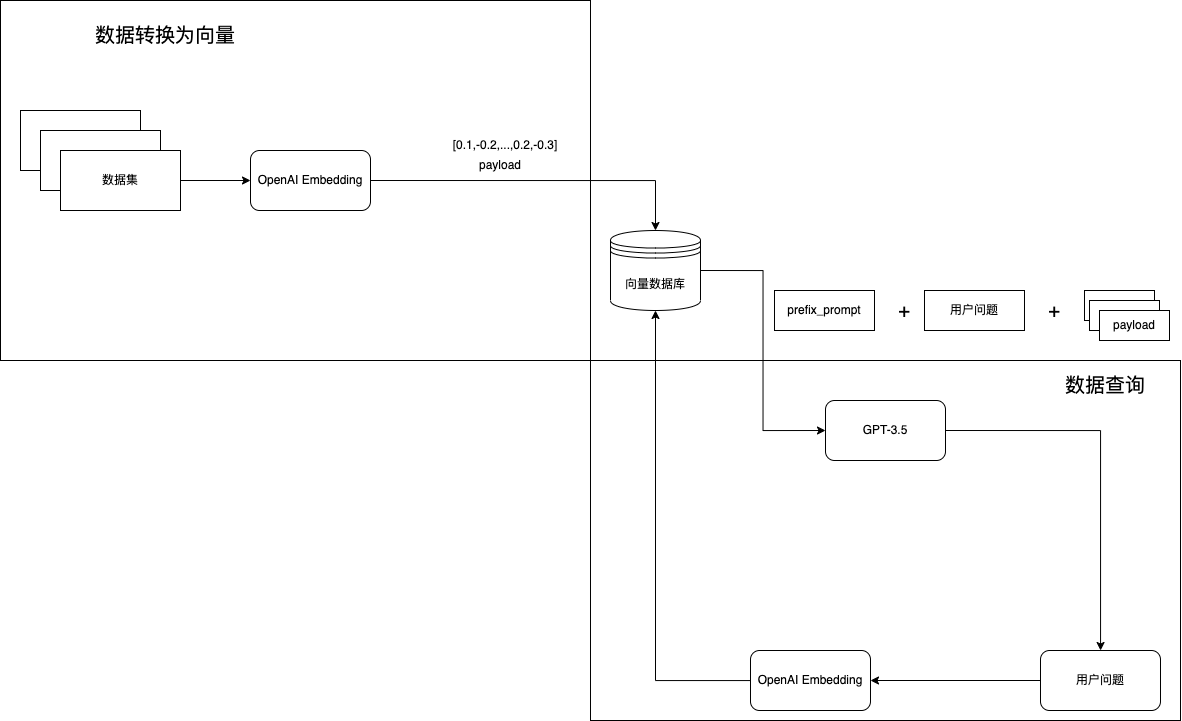
以上就是目前 ChatGPT 类领域聊天机器人的基本原理了,除了 DocsGPT,还有最近刚刚开源的项目 document.ai 都使用了类似的方法,这种方法的基本流程是:
- 将输入的所有文档数据进行向量化并存储起来
- 当聊天时,在存储的向量数据中查询出与当前聊天内容最相近的一部分文档内容
- 将上述的文档内容作为 prompts 的一部分同聊天内容一并发给 ChatGPT 进行问答
这也就完成了对特定领域信息的注入,如果要达到聊天上下文的效果,还可以把之前的聊天内容也一并带上,那么就可以带有上下文信息了。
下面是来自 document.ai 项目的流程图:
ChatGPT 的限制
但其实这种基于预检索和 prompts 的方法限制也在这里。
因为底层的 ChatGPT 的模型是一个通用模型,而 OpenAI 并没有开放 gpt-3.5-turbo 模型 fine-tune 能力,这样意味着我们无法通过 fine-tune 来训练一个自己的专属模型,只能通过 prompts 来做提示。
而 prompts 本身也有一定的限制,ChatGPT 的接口有 4096 的 max_tokens 的限制,而这个限制是指 prompts 加回答的总量,因此我们无法在 prompts 带过多的信息,而且如果要带聊天上下文的信息的话,预检索的数据量就会更小一些。这也就限制了 ChatGPT 的精确度。
以下是关于 gpt-3.5-turbo 模型的官网说明,包含了对 token 的限制以及数据集的时间区间:

尝试
于是我在想,是否可以使用能够 fine-tune 的模型来训练自己的专属模型呢?这样一来对话时将不再需要做背景知识的 prompts,因为背景知识已经被融入了这个专属模型,最多在多轮聊天中带上上下文的信息,可以使回答更智能。
由于 gpt-3.5-turbo 模型并不提供 fine-tune 能力,我们可以选用 GPT-3 的模型,如 text-davinci-003 来做 fine-tune。就像 OpenAI 在官网主页和文档中介绍的,这两个模型在表现上是非常接近的,但 gpt-3.5-turbo 模型的成本是 davinci 模型的 10%,因此推荐大家使用前者。
那么接下来的问题是我们如何使用自己的文档数据来训练一个专属模型呢?因为 davinci 模型的 fine-tune 方法是需要输入一组 prompt 和 completion 的文本对,prompt 可以是一个问题或句子填空,而 completion 就是对问题的回答或者补充填空。所以我们需要将项目文档转换成类似的形式。
此时我们又可以回到 ChatGPT 了,因为它有非常好的阅读理解能力,对于这类文本任务的处理效果很好。于是我们可以先把自己的文档拆分成一段一段的信息,然后喂给 ChatGPT 让它把这些信息转换成一个个的事实问答对,并以 JSON 形式返回回来。当所有文档都拆分好以后就变成了一大批的基于该项目事实信息的 prompts 数据。
之后将这些 prompts 数据发送给 OpenAI 的接口基于 davinci 的基础模型训练一个专属模型,等模型训练好以后就可以来尝试和自己的专属模型聊天啦。
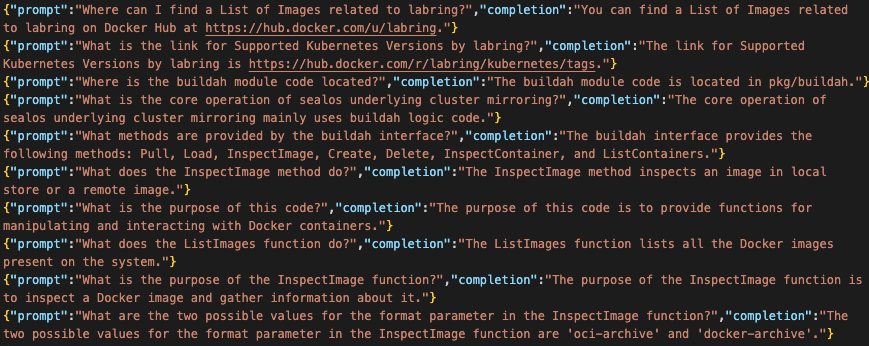
使用 Sealos 的官方文档中的 89 个 Markdown 文件得到了 1502 个问答对,其中的一些 prompts 示例如下,看起来还是非常不错的:
对比
成本
其实最大的对比还是成本的对比,ChatGPT 由于没有 fine-tune,所以成本就只有每次问答的成本,但由于大部分时候需要带大量的 prompts,其实隐性的成本是挺高的,我们经常可以看到一个简短的问题会带有上千个字符的 prompts。
而 davinci 的 fine-tune 模型的训练成本是较高的,Sealos 文档的训练一共向专属模型中输入了 25 万多个 token,训练时间 1 个小时左右,成本 8 美元。但一旦获得专属模型后,后续的聊天中就不再需要做预检索和背景知识的 prompts 了,可以直接进行关于该领域的知识问答。不仅 token 消耗会变小,而且速度也会更快。
Sealos 4.0 文档的专属模型是 davinci:ft-personal:sealos-doc-2023-03-11-13-00-02 ,有兴趣的同学可以试试,我不确定是否是所有人都可以使用的。
效果
这里我比较了一下 DocsGPT 和简单的 fine-tune 模型在 OpenDigger 下的效果。
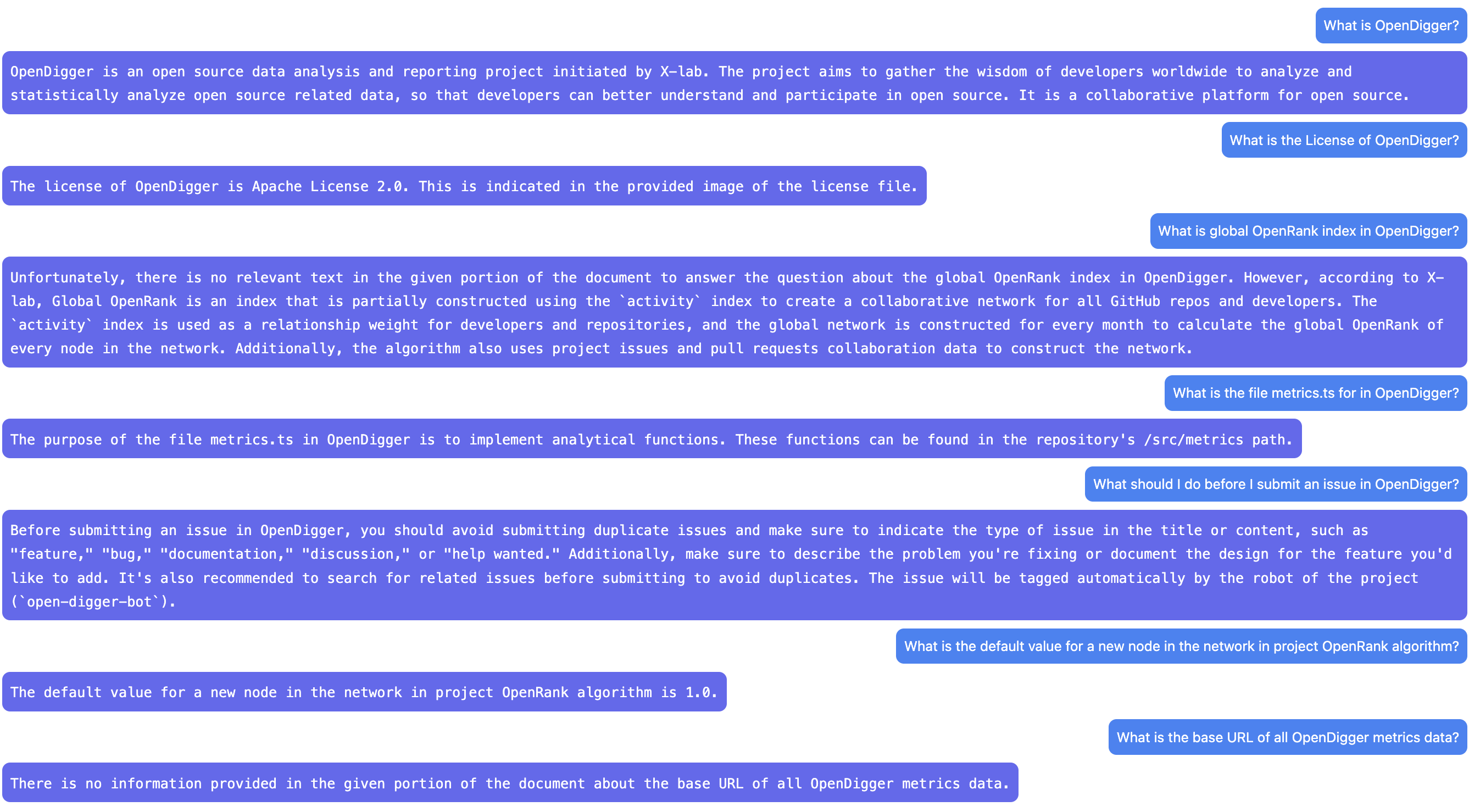

第一张是 DocsGPT 的效果,第二张是 davinci fine-tune 模型的效果。可以看到两个表现都还不错,但也存在明显的差异:基于 ChatGPT 的结果看起来更好一些,因为它具有更好的语言能力,甚至会做一些延伸和扩展,虽然有些是错误的。而专属模型的回答更加简洁,而且与 prompts 有较大的关系,因此对细节的掌握更多一些。
由于专属模型的回答与 prompts 的质量非常相关,所以更好的训练数据一定会让其表现更好。目前只是使用了最简单的 ChatGPT,而且给到的任务可能不足够好,所以结果还有提升的空间。但可以看到 ChatGPT 对于文本的理解还是很强的,尤其是对于一些结构化的文本,例如对表格的理解是很强的。如果进一步优化第一步构造 prompts 数据的逻辑,再加上一些人工的调整和修正,效果应该会更好。
未来
其实基于大模型的可能性真的非常多,有想象力的话可做的事情太多了,例如将自己的思想和博客作为输入,可以训练出一个包含自己想法的模型,然后给他一个定位是模仿人进行交流,那么就可以得到一个你的虚拟人了,很多情况下,对于领域 KOL,完全可以通过这种方式和粉丝互动,粉丝可以直接针对他的思想来进行提问和交流。
而对于不善写作的人,可以把自己的想法按照简单的问答对的形式输出来训练自己的专属机器人,再配合大模型本身的语言和逻辑能力帮助自己撰写包含自己思想的文章,应该也是非常不错的思路。
对于一个以前从来没自己做过机器学习训练的入门者,最近几天还是非常津津有味的做了一些尝试,而且效果还是比较惊艳的,也欢迎有兴趣做 prompts engineering 的同学一起交流心得。